Güncel Videolar
0
Kelime Okuma
0
Deyimler
0
Cümleler
0
Eşleşen Çizimler
0
Kodlanmış Bölümler
Voynich Nedir?
Voynich bir tarihi el yazmasının adıdır.
Voynich bir tarihi el yazmasının adıdır. Bu yazmaya onu bulduğunu söyleyen Voynich adındaki bir (eski ve değerli el yazmaları ve nadir kitapların satıcısı) sahafın adı verilmiştir. Bu yazma yaklaşık 600 yaşında ve yaklaşık 240 sayfadan oluşmaktadır. Yazma üzerinde yapılmış laboratuvar testlerinin neticelerinden aktarılan bilgiye göre bu eserin 15. yy başlarında (1404-1438) yazıldığı düşünülmektedir. Yazma kodlama ve düz yazı bölümlerden ibarettir ve düz yazı bölümleri soldan sağa doğru okunurken kodlama bölümler yukarıdan aşağı okunmaktadır. Mesela her sayfadaki her satırın ilk harfleri veya heceleri yukarıdan aşağı doğru kodlanmıştır ve kodlanan bölümler ile satırlar (yatay düz yazı) bölümleri ayrı ayrı içeriklere sahiptir. Kodlanan bölümler ve içerik yaptığımız ATA alfabe transkripsiyonu sayesinde ilk defa okunur olmuştur ve okunan bölümlerden anladığımız kadarı ile yazmanın 1453 yılından önce yazılmış olduğunu kesinlikle söyleye biliriz. Bu el yazmasının aslı bugün Amerika Birleşik Devletlerindeki Yale Üniversitesi nadir kitaplar ve el yazmaları (Beinecke Rare Book Manuscript Library) kütüphanesinde bulunmaktadır.
Yazmaya adını onu Avrupada bulduğunu söyleyen sahhafın adı verilmiştir. Biz bu yazmaya ATA El Yazması adını verdik.
ATA Alfabesi

Temel alfabe karakterleri ve ses değerleri
September,27th 2022
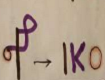
Hece karakterleri (birleşik karakterler) ses değerleri
September,27th 2022

Tanımga karakterlerinin ses değerleri
September,27th 2022

Sayısal işaretlerin ses değerleri tablosu
September,27th 2022
ATA Transkripsiyonu ve Yazarın Dili
AtaMainDescription" value="Onun yazıldığı alfabenin daha önce hiç bir yerde benzerine rastlanmamıştır. Biz bu alfabeye bir alfabe transkripsiyonu hazırladık ve ATA Transkripsiyonu adını verdik. Bu transkripsiyonu kullanarak bu yazmayı Türkçe olarak okumak mümkündür. Yazarın bugün konuşulan Türk dillerinden hangisine en yakın şekilde konuştuğunu, hangi lehçeyi kullandığını mevcut durumda tam olarak netleştirebilmemiz henüz söz konusu olmamıştır. Bu konu daha çok dil bilimcilerin alanında incelenmelidir. Bizim bugün konuşulan Türk dillerine bakarak yaptığımız çıkarım yazarın Anadolu, Azerbaycan, Özbek ağızlarının bir karışımı bir dil ile konuştuğu, yani karışık lehçe kullanarak bu eseri yazdığı yönündedir. Bir diğer olasılık yazarın kullandığı Türk dili lehçesinin bugün yaşamayan/unutulmuş lehçelerden birisi olması ihtimalidir. İşte bu alan daha çok dil bilimcilerin yorumlarına açık olduğu için biz bu sayfamızda ve yayınlarımızda yazarın dilini bazı yerlerde sadece Türkçe veya Türki anlamında (Turkic) dilli olarak anacağız, yazacağız. Bu web sayfasında bu konuda ve ATA transkripsiyonun açıklanması konusunda yaptığımız çalışmayı ve geçmiş Türk diline ait muhtelif çalışmaları bulabilirsiniz.
Sizler de okumalara katkı sağlamak isterseniz burada yayınladığımız ATA alfabe transkripsiyonunu kullanarak Ayrıca bu yazmanın sayfalarında kendi sözcük ve tümce okuma önerilerinizi yapa bilir ve arzu ederseniz bize önerilerinizi iletişim bölümünden suna bilirsiniz. Bu okumalara bu şekilde katkı yapmanız için sayfamızda kendinize ait bir kullanıcı hesabı oluşturarak çalışmalara katkı sağlayabilirsiniz.
Sizler de okumalara katkı sağlamak isterseniz burada yayınladığımız ATA alfabe transkripsiyonunu kullanarak Ayrıca bu yazmanın sayfalarında kendi sözcük ve tümce okuma önerilerinizi yapa bilir ve arzu ederseniz bize önerilerinizi iletişim bölümünden suna bilirsiniz. Bu okumalara bu şekilde katkı yapmanız için sayfamızda kendinize ait bir kullanıcı hesabı oluşturarak çalışmalara katkı sağlayabilirsiniz.
Sayfalar
Aslı Yale Üniversitesinde Berneke isimli nadir kitaplar ve el yazmaları (Yale University Beinecke Rare Book Manuscript Library) kütüphanesinde bulunan yazmanın orjinal sayfalarını bu sayfada görüntüleyebilirsiniz. ATA el yazmasının bazı sayfaları zaman içerisinde kaybolmuştur ve biz bu eksilen sayfaların Voynich ve/veya onun İşbirliği yaptığı bazı iş ortakları tarafından bu sayfaların üzerlerinde Osmanlı kütüphanelerinin sahipliğini gösteren mühürlerinin bulunması sebebi ile bilinçli, bir şekilde yırtıldığını düşünmekteyiz. Bununla ilgili daha detaylı olarak kitabımızdan bilgi edine bilirsiniz. ATA yazmanın tam olarak bugünkü Türk diline ve İngilizceye tercüme edilen sayfalarını da yine zaman zaman bu platformumuzda sizler ile paylaşacağız. Bu tercümelerin nasıl yapıldığı hakkındaki detayı da kitap çalışmamızda bulabilirsiniz. Ayrıca tam sayfa okumalarına katkı saylamak isterseniz bizimle iletişim bölümünden irtibata geçerek kendi tercüme önerinizi de suna bilirsiniz.
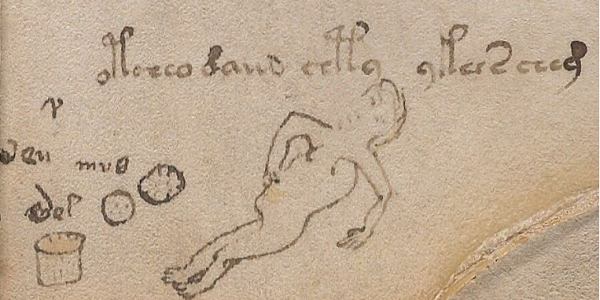
Tümceler
ATA alfabe transkripsiyonu ile yaptığımız tümce okumalarını da bu sayfamızda ve kitap ve makalelerimizden göre bilirsiniz. Bu okumaların nasıl yapıldığına ve tümcelerin Türk dili dahilinde nasıl incelenmesi gerektiğine veya tarafımızdan incelendiğine dair notlarımızı da yer yer sayfamızda göre bilirsiniz. Yeni veya varsa güncellenmiş tümce okumalarımızı da olabildiğince sık sık bu sayfamızdan güncellemeye veya duyurmaya çalışacağız. ATA alfabe transkripsiyonu yazarın bu yazmada bazı bilgileri açıkça yazmayı tercih etmemesi sebebi ile yazar tarafından bazı yazı işaretleri birden çok ses değerine karşılık gelecek şekilde kodlanmış olduğu için farklı okumalar yapmaya imkan vermektedir. Bunun tam olarak neden yapıldığını okuma örneklerini verdiğimizde daha net göreceksiniz. Bu bizim okuma yapmamızı kolaylaştırmayan aksine zorlaştıran bir durumdur. Çünkü birden fazla şekilde okunabilen işaretlerin birden fazla olasılık ile okunan anlamlı sonuçlar veren sözcükler yaratmış olması söz konusu olmuştur.

Deyimler
Siz eğer Türk dili bilen birisiyseniz, ATA yazmada bugüne kadar hiçbir Türkçe sözlükte olmayan bazı az sayıda sözcükleri görecek ve anlamlarını da hemen algılayacaksınız. Aynı şekilde bu yazma içerisinde ilk defa karşılaşacağınız deyimler de vardır. Bu deyimlerin bir kısmının da aynı şekilde daha önce hiç bir Türk dili sözlüğünde veya çalışmasında gösterilmemiş ilk defa tarafımızdan açıklanacak deyimlerden olduğunu düşünüyoruz. Bunların ne kadarı yazarın yarattığını veya ne kadarı yazarın yaşadığı dönemde yaygın olarak kullanılan deyimlerdendir bilemiyoruz. Bu yazmada bulunan deyimlere bir örnek verelim. Yazar bir sayfada 'Sapçıklı çocuk sarhoşu' sözlerini kullanmış. Bunun anlamı 'illa da erkek çocuk isteyen kimse' veya 'erkek çocuk doğmasına dair beklentisi takıntı haline gelmiş kimse' demektir. Siz de eğer yazmayı okurken yeni deyimler ile karşılaşırsanız bu tip bilinmedik veya çok bilinmedik deyimlere sizin verdiğiniz anlamları da arzu ederseniz bizimle paylaşınız.

Kelimeler
Yazmada bugüne kadar 600 adet den fazla farklı sözcük okuduk ve bu okuma işlerini boş zamanlarımızda yaptığımız için okumalar biraz ağır ilerlese de neredeyse her yeni sayfa üzerindeki detaylı çalışmamızda yeni sözcük okumaları yapıyoruz. Bu sitemizde ve belli bazı yayınlarımızda okuduğumuz sözcükleri alfabetik sıra ile yerleştirme işine devam ederek güncellemelerimizi yapacağız. Yani çalışmalar devam ettikçe okunan sözcüklerin sayısı artmaktadır. Bazı sözcükleri de bugün bulabildiğimiz hiçbir sözlükte göremiyoruz ancak bunlara kök anlamlarından hareket ile anlamlarını vermekteyiz. Ancak yazmada bulunan sözcüklerin yaklaşık olarak %20 ile %21 kadarı bugün de kullanılan sözcüklerdir. Yazar bir gezgin olarak bugünkü İtalya'dan başlayarak İstanbul'a kadar devam eden bir gezi yaptığı ve bu eseri gezi sırasında yazdığı için yazarın Türk dili dışında 600 sene evvelki Latince, Yunanca gibi bazı bölge dillerini de bildiğini tahmin etmekteyiz. Buna ilave olarak yazar muhtemelen o dönemde okur yazar pek çok Osmanlı vatandaşının da bildiği üzere Arap ve Fars dillerini de biliyor olmalıdır ve bu sebeple bu dilleri bilen kimselerin de bizim yaptığımız ATA alfabe transkripsiyonuna dayanarak sözcük okumaları yapmaya çalışmaları faydalı olacaktır. Siz de okuduğunuz sözcükleri bu sayfamız üzerinden bizimle paylaşa bilirsiniz.